Regex:
how to match non empty strings between two elements?
[Python] what is difference between re.search(), re.match() and re.findall(), when to use each of them?
[Python] how to execute multiline code in the python interpreter? use backslashes to continue on the next line
[Python] how to test if a variable is empty string or contains only space or is none? if a or a.strip(), this will first test if it's None, then test if it only contains spaces, tabs, newlines and so on.
[Python] how to test if a variable is True, False, or None?
test True: if a is True
#if a is a non-zero number, a will evaluate to true, but a number is not the same as boolean True! keep in mind of this.
test None: if a is None
#None is a special singleton object, there can only be one. Just check to see if you have that object.
test False: a not True and not None, then it's
[Python] how to check if a variable is a string?
method a: isinstance(a, str)
The isinstance function takes two arguments. The first is your variable. The second is the type you want to check for. in Python 3.x, all types are classes.
method b: if type(a) == str:
use the type built-in function to see the type of variables. None:'NoneType', booleans:'bool', strings:'str', numbers:'int','float', lists:'list', tuples:'tuple', dictionaries:'dict', ...
Tuesday, December 10, 2019
Thursday, October 10, 2019
Systemverilog simulators related
performance profile
VCS:profile in VCS by time or memory.
#for memory profiling
-simproile //compile option
-simprofile mem //simulation option
#for time profiling
-simprofile //compile options
-simprofile time //sim options
the profile report will be store at compile directory named "profilereport"
IUS:
debug sim hang by using cpu usage report
compile option: -linedebug
simulation option: -profile
at sim hang point, stop test by: Ctrl+c (1 time), then ncsim>exit
check the ncprof.out file (cpu usage summary and source code location)
Coverage
code coverage fefinition:line/statement: will not cover module/end module/comments/time scale
block: begin...end, if...else, always
expression:
branch: case
conditional: if...else, ternary operator (?:)
toggle:
FSM:
VCS:
%vcs -cm line+tgl+branch source.v
%simv -cm branch
vcs urg (Unified Report Generator):
%urg -dir simv1.vdb [simv2.dir simv3.vdb ...] -metric line+cond+branch -report specified_ouput_dir //general options
%urg ... -parallel -sub bsub -lsf "" //run urg in parallel to speed up
%urg -elfile <filename> //for exclusion files
%dve -covdir simv.vdb//view coverage db directly in DVE
Dump Waveform
1. Options
setenv FSDB_FORCE //to display forced signals in highlight in waveform viewer
2. sdf
3. use do file to control fsdb dump.
%vcs -ucli -do PATH_OF_DO_FILE //simulation options
below is a sample tcl do file:
####start of file###############
#control fsdb dump
set run_time_before_dump 0us
set dump_all 1
set run_time 400us
run $run_time_before_dump
set TOP eth_top_tb
fsdbDumpfile $TOP.fsdb
if (dump_all == 1) {
fsdbDumpvars 3 $TOP
fsdbDumpvars 0 $TOP.xxx...
fsdbDumpMDA 1 $TOP...
} esel {
...
}
run $run_time
exit
####end of file################
4.dump force information
setenv FSDB_FORCE //to display forced signals in highlight in waveform viewer
2. sdf
3. use do file to control fsdb dump.
%vcs -ucli -do PATH_OF_DO_FILE //simulation options
below is a sample tcl do file:
####start of file###############
#control fsdb dump
set run_time_before_dump 0us
set dump_all 1
set run_time 400us
run $run_time_before_dump
set TOP eth_top_tb
fsdbDumpfile $TOP.fsdb
if (dump_all == 1) {
fsdbDumpvars 3 $TOP
fsdbDumpvars 0 $TOP.xxx...
fsdbDumpMDA 1 $TOP...
} esel {
...
}
run $run_time
exit
####end of file################
4.dump force information
simv +fsdb+force
5.dump glitch info
Before VCSMX/1509,
simv +fsdb+sequential +fsdb+glitch=0 +fsdb+region
+fsdb+glitch=num,0表示所有的glitch都保存,1表示最近的glitch保存,2表示最近两个glitch被保存
After VCSMX/1509,
simv +fsdb+delta
Race Condition
VCS:
+evalorder //vcs sim option
//eval combinational group then behavioral group.
//reduce race, refer to vcs userguide
Monday, September 30, 2019
Physical layer of Networking Hardware
prbs generator:
Random bit sequence using Verilogprbs polynomials used in networking
Fibonacci form and Galois form
Fibonacci form: Another unique feature to this form is that the values in the shift register aren’t modified between when they are originally calculated and the output–making it possible to see then next LN output bits by just examining the shift register state.
I have seen it used for prbs(peudo random binary sequence in ethernet transmission protocols for scrambler/descrambler, encoding pad, random pattern generation for loopback testing, Cyclic redundancy check(CRC) and so on), timer( non linear incremental timer, as lfsr normally has a fixed perioed)
References:
wiki
Generating Pseudo-Random Numbers on an FPGA
An example LFSR
Delta-sigma modulation
Explaining SerDes:
(Chinese) SerDes Knowlege: notice the limitations of parallel transmission.
References:
wiki
Generating Pseudo-Random Numbers on an FPGA
An example LFSR
ADC OSC(oversampling ratio):
The basics of sigma delta analog-to-digital convertersDelta-sigma modulation
Explaining SerDes:
(Chinese) SerDes Knowlege: notice the limitations of parallel transmission.
circuit noises:
simultaneously switching noise an overview/Sunday, September 8, 2019
Tuesday, August 27, 2019
Digital Design Verification Subsystem Lessons Learned
- make bus randomized during invalid cycle, to catch dut bugs that did not check valid signals. However, the constraint should still give 0 bus value a weight, so that 0 bus value can happen in invalid cycle, just in case that in real chip, the bus value is gated to 0 by upper layer module.
- bugs of features that cross two subsystems are difficult to catch. if a value generated in one module, and will be used in next module, it has a higher chance to have bug uncatched, as it needs correct model behavior as real hardware. solution: a) it's better to try to implement this in the same module, instead of split it into different modules, if possible. an example is the idle insertion/deletion to accommodate the AM (alignment marker) insertion/deletion in PCS. in this case, it's better to implement it in PCS instead of in MAC.
- bugs of features that related to performance AND cross two subsystems are extremely difficult to catch. possible solutions: a) in subsystem level, force to speed up counter value count, and increase pkt counts and so on, so that the possibility is increased. however, this needs very specific test scenarios; b) use hardware acceleration or e, e.g. Palladium or Synopsys ZeBu; c) chip top test to simulate the cross subsystem behaviors
- simplify architecture based on real application. sometimes, smart design means simple brutal force. this one needs the architects sensitivity to the industry use scenarios. I have two examples: a) initially we design our switch to have all kinds of protocols and features to both be legacy device compatible and also includes new features. this leads to overdesign and many bugs (insufficient man power and verification time). however, data center ethernet switch are more focused on feed and speed, it needs high throughput, less focused on protocols. end results, a lot of features are not used, a lot of hot new architectures (like SDN) are not used. this is big waste of resources. b) ...?
- Review every registers with DE in review meetings. Need to decide for every register: a) what is its meaning and actual use case (e.g. how does software guy config it, how does SA test it in real chip); b) can it be randomized in base test or should be tested in specific test; c) does it have some values that are often used by SA and Customer in real chip? weighted distribution?
- Review base config randomization constraints for base test. this is also related to 5) as some of the configs are registers. it needs designer and SA's input to confirm.
- simulation time vs packets number: Do Not trade packets number for simulation time. Meaning that do not try to save hardware resources. For verification, the first priority is function correctness, and the more packet number, the more possible that a bug will be hit. CPU resources are cheap, real chip bugs are expensive!
- random noise register/memory access during every test. But make sure that the noise and actually traffic can actually hit the same register/memory to trigger corner bugs.
- there should be 2 types of checker for a features if it cannot be accurately checked in every scenarios: a) a specific test that accurately check it's function; b) a general checker which is enabled in every testcase, and act as a sanity checker, in case there is some fundamental bugs in certain corner cases, which was not found in the a).
- choose the constraint range carefully, and choose the random value carefully. speed mode, pkt number, and the event happen time are all related, need to consider them when setting constraint or randomization range.
- have status and counters for monitors and controlling tb in cfg or virtual interface. for example, have counter count received pkt count, or have status variable to monitor dut is in transmiting or idle state, and so on.
Tuesday, August 20, 2019
Protocols
1. IIC or I²C (Inter-Integrated Circuit)
3. UART(Universal Asynchronous Receiver/Transmitter)
freebsd Serial and UART Tutorial
The Start bit always has a value of 0 (a Space). The Stop Bit always has a value of 1 (a Mark). This means that there will always be a Mark (1) to Space (0) transition on the line at the start of every word, even when multiple word are transmitted back to back. This guarantees that sender and receiver can resynchronize their clocks regardless of the content of the data bits that are being transmitted. refer to stm32f103 reference manual S.27.3.3: 16X oversampling was used to detect noise errors.
4. ARM AMBA

From here, the rest of the transaction occurs on the read data channel. When the master is ready for data it asserts its RREADY signal. The slave then places data on the RDATA line and asserts that there is valid data (RVALID). In this case, the slave is the source and the master is the receiver. Recall that VALID and READY can be asserted in any order so long as VALID does not depend on READY. This read represents a single burst transaction made up of 4 beats or data transfers. Notice the slave asserts RLAST when the final beat is transferred.

AXI Interconnect:
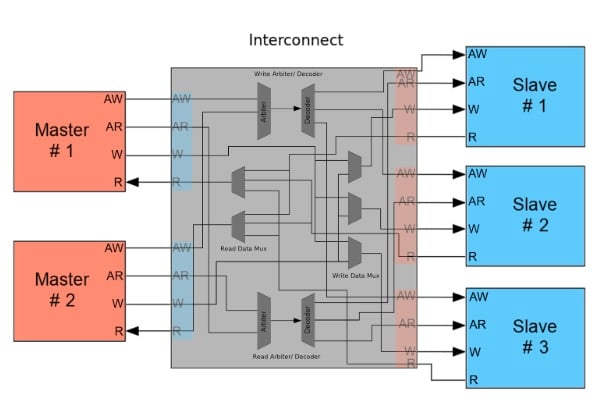
– Bus topology / routing / resources:
From this point of view, I²C is a clear winner over SPI in sparing pins, board routing and how easy it is to build an I²C network.
– Throughput / Speed:
If data must be transferred at ‘high speed’, SPI is clearly the protocol of choice, over I²C. SPI is full-duplex; I²C is not. SPI does not define any speed limit; implementations often go over 10 Mbps. I²C is limited to 1Mbps in Fast Mode+ and to 3.4 Mbps in High Speed Mode – this last one requiring specific I/O buffers, not always easily available.
– Elegance:
Both SPI and I2C offer good support for communication with low-speed devices, but SPI is better suited to applications in which devices transfer data streams, while I²C is better at multi master ‘register access’ application.
Conclusions.
In the world of communication protocols, I²C and SPI are often considered as ‘little’ communication protocols compared to Ethernet, USB, SATA, PCI-Express and others, that present throughput in the x100 megabit per second range if not gigabit per second. Though, one must not forget what each protocol is meant for. Ethernet, USB, SATA are meant for ‘outside the box communications’ and data exchanges between whole systems. When there is a need to implement a communication between integrated circuit such as a microcontroller and a set of relatively slow peripheral, there is no point at using any excessively complex protocols. There, I²C and SPI perfectly fit the bill and have become so popular that it is very likely that any embedded system engineer will use them during his/her career.
2. RTC (Real-Time Clock)3. UART(Universal Asynchronous Receiver/Transmitter)
freebsd Serial and UART Tutorial
The Start bit always has a value of 0 (a Space). The Stop Bit always has a value of 1 (a Mark). This means that there will always be a Mark (1) to Space (0) transition on the line at the start of every word, even when multiple word are transmitted back to back. This guarantees that sender and receiver can resynchronize their clocks regardless of the content of the data bits that are being transmitted. refer to stm32f103 reference manual S.27.3.3: 16X oversampling was used to detect noise errors.
4. ARM AMBA
Read Transaction:
To start the transaction off, the master places the slave's address on the ARADDR line and asserts that there is a valid address (ARVALID). Following time T1, the slave asserts the ready signal (ARREADY). Remember the source of data asserts the valid signal when information is available, while the receiver asserts the ready signal when it is able to consume that information. For a transfer to occur both READY and VALID must be asserted. All of this happens on the read address channel, with the address transfer completing on the rising edge of time T2.
Write Transaction:
What about writes? Figure 3 shows a timing diagram of an AXI write transaction. The addressing phase is similar to a read. A master places an address on the AWADDR line and asserts a valid signal. The slave asserts that it's ready to receive the address and the address is transferred.
Next, on the Write Data Channel, the master places data on the bus and asserts the valid signal (WVALID). When the slave is ready, it asserts WREADY and data transfer begins. This transfer is again 4 beats for a single burst. The master asserts the WLAST when the last beat of data has been transferred.
In contrast to reads, writes include a Write Response Channel where the slave can assert that the write transaction has completed successfully.
This is where AXI provides the most flexibility. Instead of prescribing how multi-master and multi-slave systems work, the AXI standard only defines the interfaces and leaves the rest up to the designer. If the system has multiple masters attempting to communicate with a single slave, then the AXI Interconnect may contain an arbiter that routes data between the master and slave interfaces. This arbiter could be implemented using simple priorities, a round-robin architecture, or whatever suits the designer's needs.
Systems that use multiple masters and multiple slaves could have interconnects containing arbiters, decoders, multiplexers, and whatever else is needed to successfully process transactions. This might include logic to translate between AXI3, AXI4, and AXI4-Lite protocols.
Additionally, interconnects can perform bus-width conversion, use data FIFOs, contain register slices to break timing paths, and even convert between two different clock domains.
Burst len, size, type:
The burst length for AXI3 is 1~16, for AXI4 is 1~256(INCR) and 1~16(other burst type)
Burstsize: the maximum number of bytes to transfer in each data transfer, or beat, in a burst.
If the AXI bus is wider than the burst size, the AXI interface must determine from the transfer address which byte of lanes of the data bus to use for each transfer. See Data read and write structure on axi spec.
The size of any transfer must not exceed the data bus width of either agent in the transaction.
Interesting history: Why a burst cannot cross a 4KB address boundary
Out of order:
Data from read transaction ARID values can arrive in any order
Interleave:
Read data of transaction with different ARID values can be interleaved
Write Interleaved: AXI3 support, but the first item of write data must be issued in the same order as the write address. AXI4 does not support interleave.
MIB RFC:
RFC2819 : Remote Network Monitoring Management Information Base
RFC2863: The Interfaces Group MIB
RFC3273: Remote Network Monitoring Management Information Base for High
RFC4836: Definitions of Managed Objects for IEEE 802.3 Medium Attachment Units (MAUs)
RFC3635: Definitions of Managed Objects for the Ethernet-like Interface Types
PFC MIB counter
Networking Protocols:
1. What is the exact difference between SGMII and 1000Base-X?
Unaligned Address:
TODO
AXI response
5. USB2.0
USB2 made simple(better and low level)
USB in a nutshell(introductory)
6. SPI
MIB RFC:
RFC2819 : Remote Network Monitoring Management Information Base
RFC2863: The Interfaces Group MIB
RFC3273: Remote Network Monitoring Management Information Base for High
RFC4836: Definitions of Managed Objects for IEEE 802.3 Medium Attachment Units (MAUs)
RFC3635: Definitions of Managed Objects for the Ethernet-like Interface Types
PFC MIB counter
Networking Protocols:
1. What is the exact difference between SGMII and 1000Base-X?
Tuesday, July 23, 2019
Perl Notes
system()
Using the Perl system() functionThe system() function returns two numeric values folded into one. The first is the Unix signal (e.g INT=2, QUIT=3, KILL=9), if any, that terminated the command. This is stored in the lower eight bits returned. The next higher eight bits contain the exit code for the command you executed.
The result is a compound numeric value, not a logical value. This also reads inverted and is confusing. If you need more information on error, then you can break up the return code:
my $status = system("rotate_quickly.pl");
my $signal = $status & 0xff;
my $exit_code = ($status >> 8) & 0xff;
String
how to keep all special characters in a string?
the use of q() and quotemeta: stackoverflow post on excaping in perl
Monday, July 15, 2019
UVM Notes
This article is to list down the most used constructions of UVM to my personal understanding.
2) a specialized cfg task is set_config_* for uvm_component class, where * can be int, string or object, depending on type of config property:
1) `uvm_field_int (<field_name>, <flags>)
2) `uvm_field_object (<field_name>, <flags>)
3) `uvm_field_string (<field_name>, <flags>)
4) `uvm_field_event (<field_name>, <flags>)
#static Array:
1) `uvm_field_sarray_enum (<enum_type>, <field_name>, <flags>)
2) `uvm_field_sarray_int (<field_name>, <flags>)
3) `uvm_field_sarray_object (<field_name>, <flags>)
4) `uvm_field_sarray_string (<field_name>, <flags>)
#dynamic Array:
1) `uvm_field_array_enum (<enum_type>, <field_name>, <flags>)
2) `uvm_field_array_int (<field_name>, <flags>)
3) `uvm_field_array_object (<field_name>, <flags>)
4) `uvm_field_array_string (<field_name>, <flags>)
#dynamic Array:
1) `uvm_field_queue_enum (<enum_type>, <field_name>, <flags>)
2) `uvm_field_queue_int (<field_name>, <flags>)
3) `uvm_field_queue_object (<field_name>, <flags>)
4) `uvm_field_queue_string (<field_name>, <flags>)
#associative Array:
1) `uvm_field_aa_<d_type>_<ix_type>
UVM simulator steps
- VCS(Synopsys)
- IUS(Cadence)
- Questa(Mentor)
1. set $UVMHOME to instal dir of required UVM library
2. Use irun option -uvmhome to reference $UVMHOME
3. Use incdir to reference any included file directories
%irun -f run.f
run.f:
-uvmhome $UVMHOME
-incdir .../sv
.../sv/tb_pkg.sv
top.sv
top.sv:
module top();
import uvm_pkg::*;
import tb_pkg::*;
initial begin
//run test
...
end
endmodule: top
Debugging case:
when using 3 step compile on vcs, vlogan and elab must both add uvm_dpi.cc to actually compile the c. add the file in file list does not work.
if using 1 step compile, then just need to include the file in filelist.
UVM Directory Structure
contains two kinds of code:
UVM_ROOT UVM_TOP
Tips: (1) debug features
uvm_top.print_topology(); //advised to be called from end_of_elaboration_phase
=======================================
If you look into the uvm source code, run_test() task is actually a task defined in the class uvm_root. it's the implicit top-level and phase controller for all UVM components. the UVM automatically creates a single instance of <uvm_root> that users can access via the global (uvm_pkg-scope) variable uvm_top.
- long time confusion solved: the run_test() called in top tb module is defined in uvm_globals.svh which actually calls the run_test() in uvm_root.
- uvm_test_top is not a variable in uvm_root, how can you access that with uvm_root?
- class uvm_root extends uvm_component
- const uvm_root uvm_top = uvm_root::get();
- uvm_top is the top-level component, and any component whose parent is specified as NULL becomes a child of uvm_top.
- uvm top manages the phasing for all components.
- set globally the report verbosity, log files, and actions(?).
- Because uvm_top is globally accessible (in uvm_pkg scope(?)), UVM's reporting mechanism is accessible from anywhere outside uvm_component, such as in modules and sequences.
UVM Configuration
1) uvm_config_db- uvm_config_db#(int)::set(this, "env.agent", "is_active", UVM_PASSIVE);
- uvm_config_db#(int)::set(null, "uvm_test_top.env.agent", "is_active", UVM_PASSIVE);
- uvm_config_db#(int)::set(uvm_root::get(), "uvm_test_top.env.agent", "is_active", UVM_PASSIVE);//equivalent to using null
- uvm_config_db#(int)::set(null, "*.env.agent", "is_active", UVM_PASSIVE);
- uvm_config_db#(int)::set(null, "uvm_test_top.env*", "is_active", UVM_PASSIVE);
- Database must be type parameterized. this allows config db to be created for any standard or user-defined type; and allows better compile time checking.
- Methods are static
- Methods use a specific contxt argument, whi is usually this; unless the set is called from the top module, in which case it must be assigned to null
- syntax: static function void set(uvm_component cntxt, string inst_name, string field_name, ref T value)
- syntax: static function void get(uvm_component cntxt, string inst_name, string field_name, ref T value)
- get is only required when set is called from the top level module or outside the build phase
- syntax: static function bit exists(uvm_component cntxt, string inst_name, string field_name, bit spell_chk = 0)
- syntax: static task wait_modified(uvm_component cntxt, string inst_name, string field_name)
- inst_name may contain wildcards or regular expression syntax
- for object, interfaces or user-defined types, use uvc_config_db
- for run-time configuration, use uvc_config_db
2) a specialized cfg task is set_config_* for uvm_component class, where * can be int, string or object, depending on type of config property:
- config settings are automatically resolved in UVM build phase; that is because apply_config_settings() is executed in the build phase (when super.build_phase() is called in any uvm_component class). settings are applied only when match is found, if not found, field names will be unset, and mismatched configuration set's should be listed at end of simulation.
- syntax: virtual function void set_config_in (string inst_name, string field, bitstream_t value)
- inst_name is relative pathname to a specific component instance from the component where the method is called
- field is a string containing a config property name of the instance class
- set build options before calling super.build_phase; this is also why the parameters are strings, because the components and fields does not exist yet.
- set_config_int("env.agent", "is_active", UVM_PASSIVE);
- set_config_int("*", "recording_detail", 1);//default is 0, by enabling the recording details for every component, transactions can be viewed in the waveform window(?)
- the creation of the agent instance in the parent build_phase() triggers the execution of the build_phase() of the agent instance.
- config property must be automated in the component where declared (field registered)
- Config settings in higher scope take precedence over lower scopes.
- Config settings in the same scope conform to "last one in wins"
UVM Field Automation
#Non-array1) `uvm_field_int (<field_name>, <flags>)
2) `uvm_field_object (<field_name>, <flags>)
3) `uvm_field_string (<field_name>, <flags>)
4) `uvm_field_event (<field_name>, <flags>)
#static Array:
1) `uvm_field_sarray_enum (<enum_type>, <field_name>, <flags>)
2) `uvm_field_sarray_int (<field_name>, <flags>)
3) `uvm_field_sarray_object (<field_name>, <flags>)
4) `uvm_field_sarray_string (<field_name>, <flags>)
#dynamic Array:
1) `uvm_field_array_enum (<enum_type>, <field_name>, <flags>)
2) `uvm_field_array_int (<field_name>, <flags>)
3) `uvm_field_array_object (<field_name>, <flags>)
4) `uvm_field_array_string (<field_name>, <flags>)
#dynamic Array:
1) `uvm_field_queue_enum (<enum_type>, <field_name>, <flags>)
2) `uvm_field_queue_int (<field_name>, <flags>)
3) `uvm_field_queue_object (<field_name>, <flags>)
4) `uvm_field_queue_string (<field_name>, <flags>)
#associative Array:
1) `uvm_field_aa_<d_type>_<ix_type>
#flags
UVM_NOVOMPARE
#the do_* functions are worth more discussion later.
uvm_factory
b extends a, c extends a, override(a,c)
will b be affected?
Tips: (1) how to use factory debug features.
uvm_factory::get().print(); //prints the uvm_factory details like registration and override. can be called from build phase, connect phase or mostly likely end_of_elaboration_phase.
UVM Phasing
Tips:(1) phasing debug features (not very useful)
sim option +UVM_PHASE_TRACE
(2) objection debugging
sim option +UVM_OBJECTION_TRACE
UVM_sequence
start_item()
finish_item()
get_response()
driver:
seq_item_port.get_next_item(),
seq_item_port.item_done(),
seq_item_port. put(resp)
UVM_POOL
uvm_object_string_pool #(T)
pool.get(string) #get object by a name
Scoreboard
A scoreboard normally consists of 3 components of functions:
1) reference model/transfer function
c++, systemC or systemverilog: a) existing C model; b) create model, not in collaboration with design team( duplication of errors)
2) Data Storage
model output instant, DUT takes time to output. Need to store data (and synchronization)
Queue: output data in same order as input order
Associative Array: out of order output. Key unique and knonw for input and output. herefore, key is either: a) untransformed port of data, or b) can be generated from data
3) comparison/check logic
Scoreboard internals:
update counter, tracking received, dropped, matched, and mismatched
report_phase, print summary of statistics
end of simulation: check scoreboard queues are empty
Scoreboard must create a new copy of received data item by cloning, before writing the cloned packet to the queue.
Scoreboard internals:
update counter, tracking received, dropped, matched, and mismatched
report_phase, print summary of statistics
end of simulation: check scoreboard queues are empty
Scoreboard must create a new copy of received data item by cloning, before writing the cloned packet to the queue.
UVM TLM Communication bwtween Components
TLM concepts: Port and Imp
Data Flow: producer create data, consumer consume data
Producer ---data---> Cosumer
Control Flow: Initiator sends request to Target
Initiator ---request---> Target
producer is initiator: write operation, also called push/put: e.g. analysis connections
producer is target: read operation, also called pull/get
Port: TLM connection object for Initiator
Imp (implementation): TLM connection object for target.
Export:
symbols: square(port), circle(imp), triangle(export)
port.connect(Imp)
port.connect(Export)
TLM Analysis Interface
uvm_analysis_port #(data type) ap_out
ap_out = new("ap_out", this);
`uvm_analysis_imp_decl(_foo)
uvm_analysis_imp_foo #(data type) foo_in
`uvm_analysis_imp_decl(_bar)
uvm_analysis_imp_foo #(data type) bar_in
function void write_foo(input ---);
endfunction
function void write_bar(input---);
endfunction
...ap_out.connect(...ap_in)
Complex Module UVC connection(external to intermal)
two ways:
1. Module monitor: all external connections are made to this monitor and monitor is responsible for routing connections to other component in the UVC.
the good: Single, central location for connecting external TLM interfaces.
the bad: at the expense of additional internal interface connections to other components.
2. Module connections: external TLM interfaces are placed on UVC itself, then routed using hierarchical connections and not separate TLM interface. use of TLM export object
the good: fewer TLM connections
the bad: losing some readability
Port initiators can be connected to port, export, or imp targets.
Export initiators can be connected to export or imp targets.
Imp cannot be a connection initiator. Imp is a target only, and is always the last connections object on a route.
TLM FIFO
Analysis FIFO
uvm_tlm_analysis_fifo is a specialization of uvm_tlm_fifo:
unbounded (size=0)
analysis_export replaces put export, support analysis write method.
uvm_analysis_port ---> analysis_export---analysis_fifo---get_peek_export <---scoreboard_get_port
uvm_tlm_analysis_fifo #(data type) tb_fifo = new("...", this);
uvm_get_port $(data type) sb_in = new("...", this);
function void connect_phase();
sb_in.connect(tb_fifo.get_peek_export)
endfunction
by the way, analysis fifo's blocking_get_export is just an alias to get_peek_export
Data Flow: producer create data, consumer consume data
Producer ---data---> Cosumer
Control Flow: Initiator sends request to Target
Initiator ---request---> Target
producer is initiator: write operation, also called push/put: e.g. analysis connections
producer is target: read operation, also called pull/get
Port: TLM connection object for Initiator
Imp (implementation): TLM connection object for target.
Export:
symbols: square(port), circle(imp), triangle(export)
port.connect(Imp)
port.connect(Export)
TLM Analysis Interface
uvm_analysis_port #(data type) ap_out
ap_out = new("ap_out", this);
`uvm_analysis_imp_decl(_foo)
uvm_analysis_imp_foo #(data type) foo_in
`uvm_analysis_imp_decl(_bar)
uvm_analysis_imp_foo #(data type) bar_in
function void write_foo(input ---);
endfunction
function void write_bar(input---);
endfunction
...ap_out.connect(...ap_in)
Complex Module UVC connection(external to intermal)
two ways:
1. Module monitor: all external connections are made to this monitor and monitor is responsible for routing connections to other component in the UVC.
the good: Single, central location for connecting external TLM interfaces.
the bad: at the expense of additional internal interface connections to other components.
2. Module connections: external TLM interfaces are placed on UVC itself, then routed using hierarchical connections and not separate TLM interface. use of TLM export object
the good: fewer TLM connections
the bad: losing some readability
Port initiators can be connected to port, export, or imp targets.
Export initiators can be connected to export or imp targets.
Imp cannot be a connection initiator. Imp is a target only, and is always the last connections object on a route.
TLM FIFO
Analysis FIFO
uvm_tlm_analysis_fifo is a specialization of uvm_tlm_fifo:
unbounded (size=0)
analysis_export replaces put export, support analysis write method.
uvm_analysis_port ---> analysis_export---analysis_fifo---get_peek_export <---scoreboard_get_port
uvm_tlm_analysis_fifo #(data type) tb_fifo = new("...", this);
uvm_get_port $(data type) sb_in = new("...", this);
function void connect_phase();
sb_in.connect(tb_fifo.get_peek_export)
endfunction
by the way, analysis fifo's blocking_get_export is just an alias to get_peek_export
Wednesday, July 10, 2019
Ethernet Protocol Notes
Gigabit Ethernet:
this post is about 1G Physical Coding Sublayer (PCS), and explains scrambler/descrambler. Note the way it explains Bit Error Rate (BER).
Gigabit Ethernet 1000BASE-T
scrambling -> Spread Spectrum
this post is about 1G Physical Coding Sublayer (PCS), and explains scrambler/descrambler. Note the way it explains Bit Error Rate (BER).
Gigabit Ethernet 1000BASE-T
scrambling -> Spread Spectrum
Thursday, May 30, 2019
Digital Design and Computer Architecuture Study Notes
Bottome-up progression:
Number system -> Boolean algebra -> Boolean algebra using electrical switches -> Logic Gates -> addition (base of all calculation) -> subtraction -> combinational(NO FEEDBACK) without feedback, value change immediately (unstable) & sequential(FEEDBACK) feedback can make state(stable) -> memory, calculation without memory is not very useful -> Conditional Jump (Controlled repetition or looping is what separates computers from calculators.)
Power Consumption:
-Pdynamic = 1/2*CVDD**2f; Voltage on the capacitor switches at frequency f, it charges the capacitor f/2 times and discharges it f/2 times per second. Discharging does not draw energy from the power supply.
-Pstatic = IDD*VDD
Logic Gates:
-NOT Gate, Buffer, AND Gate, OR Gate, XOR, NAND, NOR, Transmission Gate
Combinational Logic:
characterized by its propagation delay and contamination delay. The propagation delay, tpd, is the maximum time from when an input changes until the output or outputs reach their final value. The contamination delay, tcd, is the minimum time from when an input changes until any output starts to changes its value.Combinational logic has no cyclic paths and no races. If inputs are applied to combinational logic, the outputs will always settle to the correct value within a propagation delay.
-Building blocks: full adders, seven-segment display decoders, multiplexer, decoder, priority circuits, arithmetic circuits
-Boolean algebra
-Karnaugh maps: works well for problems with up to four variables. More importantly they give insight into manipulating Boolean equations. Gray code. Dont care for output can be treateed as either 0's or 1's at the designer's discretion.
-Glitches: insight from Karnaugh maps
Sequential Logic:
SR Latch:D Latch: copies D to Q when clk is 1
D flip-flop: copies D to Q on the rising edge of the clock, and remembers it's state at all other times
synchronous sequential circuit composition teaches us that a circuit is a synchronous sequential circuit if it consists of interconnected circuit elements such that:
-Every circuit element is either a register or a combinational circuit
-At least one circuit element is a register
-All registers receive the same clock signal
-Every cyclic path contains at least one register
-Building blocks: arithmetic circuits, counters, shift registers, memory arrays, and logic arrays.
Finite state machine:
-An FSM consists of two blocks of combinational logic, next state logic and output logic, and a register that stores the state.-There are two general classes of finite state machines: Moore machines (the outputs depend only on the current state of the machine), and Mealy machines (the outputs depend only on both the current state and the current inputs).
-HDL descriptions of state machines are correspondingly divided into three parts to model the state register, the next state logic, and the output logic.
Verilog Blocking and Nonblocking Assignement:
-Use always @ (posedge clk) and nonblocking assignments to model synchronous sequential logic.always @ (posedge clk)
begin
n1 <= d; //nonblocking
q <= n1; //nonblocking
end
-Use continous assignments to model simple combinational logic.
assign y = s ? d1 : d0;
-Use always @ (*) and blocking assignments to model more complicated combinational logic where the always statement is helpful
(A case statement implies combinational logic if all possible input combinations are defined; otherwise it implies sequential logic, because the output will keep its old value in the undefined cases.)
(If statement implies combinational logic, if all possible inputs combinations are handled; otherwise it produces sequential logic.)
(It is good practice to use blocking assignments for combinational logic and nonblocking assignments for sequential logic.)
(Signals in always statement and initial statement must be declared as reg type)
(Not that signal must be declared as reg because it appears on the left hand side of a <= or = sign in an always statement. Nevertheless, it does not mean it's the output of a register, and it can be the output of a combinational logic.)
always @ (*)
begin
p = a^ b; //blocking
g = a & b;//blocking
s = p ^ cin;
cout = g | (p & cin);
end
-Do not make assignments to the same signal in more than one always statement or continuous assignment
-assign statemns must be used outside always statements and are also evaluated concurrently. a type of continuous assignment.
-case statement and if statements must appear inside always statements.
Verilog
-verilog provide generate statements to produce a variable amount of hardware depending on the value of a parameter. generate supports for loops and if statements to determine how many of what types of hardware to produce.
-Testbenches use the === and !=== operators for comparisons of equality and inequality respectively, because these operators work correctly with operands that could be x or z.
-the For loop, can be either synthesizable, where it is used to simply expand replicated logic, and they do not loop like in a c program; it can also be non synthesizable, behave like a c program, can have delay in side, not in always statement?.
-Understand the following:
1) reg and wire (Berkeley CS150)
reg is a confusing term, it is used for anything that holds data. wire cannot retain any data, henceforth it must be driven by continuous assignments.
read 2) to understand what is state.
wire: continuous assignment only, can resolve multiple driver.
reg: a language failure, it's just a varialbe, nothing to do with register. can hold varaible, therefore procedural assignment. cannot be multiple driver. can model both combinational and sequential logic.
2) Inferred Latch (stackoverflow)3) blocking and non-blocking
4) a neat blinky
5) port connection data types wire or reg: (refer to Verilog HDL by Samire Palnitkar)
port as internal unit and external input.
any side that is the data source, it can be either types. (external inputs, or internal outputs)
any side that is the data monitor, it must be net type so can be continuously assigned. (internal inputs, inout, or external outputs). a module instantiation is to connect the input/output signals continuously. so the internal input must be net, and the external output must be net, as it is implicitly driven continuously.
Friday, April 19, 2019
Linux command line notes
Questions:
1. i'm the owner of a file, but i cannot delete the file, why? (a tricky problem i encountered before, it is because you must have write permission to the parent directory before you can delete the file)
readlink:
readlink -f file_relative_path #prints the absolute path of a file or symbolic link
#-f the last component of the path must exist
diff:
1. recursively diff files in two direcotries:
diff -r dir0 dir1
2. -q consice output showing only the differences
3. tkdiff is a guide version, not very useful, but still works in some case. (gvim -d is much better in accuracy)
4. diff --suppress-common-lines -y file1 file2 | wc -l (count number of differences)
uniq:
#to reorge and remove duplicate lines for input
%uniq
#to only show the duplicated entries of original input, very useful
%uniq -d
#to only show the uniq lines of the original input
%uniq -u
#easy one to find the duplicated files (same filenames)
%find . -type f -execdir echo {} ';'|sort|uniq -d
cp:
cp --parents sourc destdir #keep full source directory path, warning: the destdir must be an existing directory name
awk:
%awk -F":" -v OFS=',' '{print $1, $2, 9}' fname
#substitue, eg. removing white space
%awk '{gsub(/ /, ""); print $2}'
sed 's/word1/word2/g' input.file > output.file
sed (Stream EDitor):
sed 's/word1/word2/g' input.filesed 's/word1/word2/g' input.file > output.file
#in-place change file
sed -i 's/word1/word2/g' input.file
sed -i -e 's/word1/word2/g' -e 's/xx/yy/g' input.file
## use + separator instead of /
sed -i 's+regex+new-text+g' file.txt
## you can add I option to case insensitive search, only works with GNU sed.sed -i 's/word1/word2/g' input.file
sed -i -e 's/word1/word2/g' -e 's/xx/yy/g' input.file
## use + separator instead of /
sed -i 's+regex+new-text+g' file.txt
sed -i 's/word1/word2/gI' input
# use ; to concatenate multiple expressions
sed -e 's/word1/word2/g;s/word3/word4/g' #equivalent to below
sed -e 's/word1/word2/g' -e 's/word3/word4/g'
#cool trick in MAC to do equivalent to tree
%alias tree="find . -print | sed -e 's;[^/]*/;|____;g;s;____|; |;g'"
#bulk replacement of string for whole folder
find . -type f| xargs see -i ‘s/pattern_org/pattern_new/g’
Clearly using xargs is far more efficient. In fact several benchmarks suggest using xargs over exec {} is six times more efficient.
#-t will print each command, then immediately execute it:
find . -name "filename" | xargs -t tail
%sleep 5s #delay 5 seconds, m: minute, h: hour, d: day.
xargs:
Linux and Unix xargs command tutorial with examplesClearly using xargs is far more efficient. In fact several benchmarks suggest using xargs over exec {} is six times more efficient.
#-t will print each command, then immediately execute it:
find . -name "filename" | xargs -t tail
#you can use -I to define a place-holder which will be replaced with each value of the arguments fed to xargs. For example ({} can be changed to any replace_string),
ls -1 | xargs -I '{}' echo '{}'
xargs -I '{}' tail '{}'/'{}'.run.log
#-i behaves like -I , except that the placeholder is
optional. If you omit the placeholder string, it defaults to the string {
}.
ls -1 | xargs -i echo '{}'
ls -1 | xargs -i echo '{}'
find and grep:
FIND -EXEC VS. FIND | XARGS#!!!find by default wont follow symbolic link, to enable it use "-L", man for help
find xxx -L
#find files but not directory names
find . -type f
#find files but not directory names
find . -type f
#find directories
find . type d
#find files specify depth
find . -maxdepth 2
#TODO: -print option?
#find with inode number
find . -inum <234567>
#find files specify depth
find . -maxdepth 2
#TODO: -print option?
#find with inode number
find . -inum <234567>
#follow symbolic link, except when broken
find . -name xxx -L
#find symbolic links
find . -type l
#find but do not print the directory hierarchy
find . [other options] -execdir echo {} ';'
map Caps Lock to Ctrl key in Gnome
curl -o [shortname] [url] #save file as another name
curl -o ~/Desktop/localexample.dmg http://url-to-file/example.dmg #save to another directory
curl -o /dev/null http://speedtest.wdc01.softlayer.com/downloads/test10.zip #test download speed with curl
curl -O [URL 1] [URL 2] [URL 3] #download multiple files concurrently
curl -L -O -C - url #Use "-C -" to tell curl to automatically find out where/how to resume the transfer. It then uses the given output/input files to figure that out.
-L #Follow location if HTTP 3xx status code found. For example, redirect url. in this case, if -L is ommitted, the actual file will not be downloaded
curl Command Resume Broken DownloadHow to Run Speed Test from the Command Line to Check Internet Connection Speed
# download all jpg files named cat01.jpg to cat20.jpg
curl -O http://example.org/xyz/cat[01-20].jpg
Other useful options are:
--referer http://example.org/ → set a referer (that is, a link you came from)
--user-agent "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET CLR 1.1.4322)" → set user agent, in case the site needs that.
xterm:
#send a terminal to another host
xterm -display <IP>:0
xterm -display <hostname>:0
# download a file
wget http://example.org/somedir/largeMovie.mov
# download website, 2 levels deep, wait 9 sec per page
wget --wait=9 --recursive --level=2 http://example.org/
Some sites check on user agent. (user agent basically means browser). so you might add this option “--user-agent=”.
wget http://example.org/ --user-agent='Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.96 Safari/537.36'
wget -r -np -k http://www.ime.usp.br/~coelho/mac0122-2013/ep2/esqueleto/
use -r (recursive), -np (don't follow links to parent directories), and -k to make links in downloaded HTML or CSS point to local files
Other useful options:
-nd (no directories): download all files to the current directory
-e robots.off: ignore robots.txt files, don't download robots.txt files
-A png,jpg: accept only files with the extensions png or jpg
-m (mirror): -r --timestamping --level inf --no-remove-listing
-nc, --no-clobber: Skip download if files exist
tar -cvf fileName.tar file1 file2 file3
tar -cvf fileName.tar dir1 dir2 dir3
tar -cvf fileName.tar file1 dir1
#to compress
$ tar -cvzf docs.tar.gz /home/vivek/Documents/
$ tar -cvjf docs.tar.bz2 /home/vivek/Documents/
#to list contents of tar
$ tar -tvf docs.tar
$ tar -tvzf docs.tar.gz
$ tar -tvjf docs.tar.bz2
#to extract
$ tar -xvf docs.tar
$ tar -xvzf docs.tar.gz
$ tar -xvjf docs.tar.bz2
For example, here's what i use to sync/upload my website on my local machine to my server.
rsync -z -a -v -t --exclude="*~" --exclude=".DS_Store" --exclude=".bash_history" --exclude="*/_curves_robert_yates/*.png" --exclude="logs/*" --exclude="xlogs/*" --delete --rsh="ssh -l joe" ~/web/ joe@example.com:~/
-a → archived mode, basically making the file's meta data (owner/perm/timestamp) same as the local file (when possible) and do recursive (i.e. Upload the whole dir).
cURL:
curl -O [url] #save to local with the save file namecurl -o [shortname] [url] #save file as another name
curl -o ~/Desktop/localexample.dmg http://url-to-file/example.dmg #save to another directory
curl -o /dev/null http://speedtest.wdc01.softlayer.com/downloads/test10.zip #test download speed with curl
curl -O [URL 1] [URL 2] [URL 3] #download multiple files concurrently
curl -L -O -C - url #Use "-C -" to tell curl to automatically find out where/how to resume the transfer. It then uses the given output/input files to figure that out.
-L #Follow location if HTTP 3xx status code found. For example, redirect url. in this case, if -L is ommitted, the actual file will not be downloaded
curl Command Resume Broken DownloadHow to Run Speed Test from the Command Line to Check Internet Connection Speed
# download all jpg files named cat01.jpg to cat20.jpg
curl -O http://example.org/xyz/cat[01-20].jpg
Other useful options are:
--referer http://example.org/ → set a referer (that is, a link you came from)
--user-agent "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; .NET CLR 1.1.4322)" → set user agent, in case the site needs that.
xterm:
#send a terminal to another host
xterm -display <IP>:0
xterm -display <hostname>:0
wget:
# download a filewget http://example.org/somedir/largeMovie.mov
# download website, 2 levels deep, wait 9 sec per page
wget --wait=9 --recursive --level=2 http://example.org/
Some sites check on user agent. (user agent basically means browser). so you might add this option “--user-agent=”.
wget http://example.org/ --user-agent='Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.96 Safari/537.36'
wget -r -np -k http://www.ime.usp.br/~coelho/mac0122-2013/ep2/esqueleto/
use -r (recursive), -np (don't follow links to parent directories), and -k to make links in downloaded HTML or CSS point to local files
Other useful options:
-nd (no directories): download all files to the current directory
-e robots.off: ignore robots.txt files, don't download robots.txt files
-A png,jpg: accept only files with the extensions png or jpg
-m (mirror): -r --timestamping --level inf --no-remove-listing
-nc, --no-clobber: Skip download if files exist
tcsh:
Learn X in Y minutes where X=tcshtar:
#to tartar -cvf fileName.tar file1 file2 file3
tar -cvf fileName.tar dir1 dir2 dir3
tar -cvf fileName.tar file1 dir1
#to compress
$ tar -cvzf docs.tar.gz /home/vivek/Documents/
$ tar -cvjf docs.tar.bz2 /home/vivek/Documents/
#to list contents of tar
$ tar -tvf docs.tar
$ tar -tvzf docs.tar.gz
$ tar -tvjf docs.tar.bz2
#to extract
$ tar -xvf docs.tar
$ tar -xvzf docs.tar.gz
$ tar -xvjf docs.tar.bz2
rsync:
Linux: Sync Across Machines, rsyncFor example, here's what i use to sync/upload my website on my local machine to my server.
rsync -z -a -v -t --exclude="*~" --exclude=".DS_Store" --exclude=".bash_history" --exclude="*/_curves_robert_yates/*.png" --exclude="logs/*" --exclude="xlogs/*" --delete --rsh="ssh -l joe" ~/web/ joe@example.com:~/
-a → archived mode, basically making the file's meta data (owner/perm/timestamp) same as the local file (when possible) and do recursive (i.e. Upload the whole dir).
-P or --progress: this will nicely show the progress of copying
-z → use compression for transmission. (compress files first, transmit, uncompress. This saves bandwidth.)
-v → verbose mode. Print out which files is being updated.
-t → copy timestamp from source to destination. If you don't, rsync will basically update every file. Timestamp is used by rsync to check if file's been updated. -a implies -t.
--exclude=glob_pattern → ignore file names that matches glob_pattern in source directory. (i.e. if it matches, don't upload it, nor delete it on remote server) For example, *.javac means all files ending in .javac
--delete → if a file/dir in destination is not in source directory, delete it.
-z → use compression for transmission. (compress files first, transmit, uncompress. This saves bandwidth.)
-v → verbose mode. Print out which files is being updated.
-t → copy timestamp from source to destination. If you don't, rsync will basically update every file. Timestamp is used by rsync to check if file's been updated. -a implies -t.
--exclude=glob_pattern → ignore file names that matches glob_pattern in source directory. (i.e. if it matches, don't upload it, nor delete it on remote server) For example, *.javac means all files ending in .javac
--delete → if a file/dir in destination is not in source directory, delete it.
-n this is cool dry run option, see what will be copied before performing real operation, and if everything is ok, remove -n from command line.
Here's a example of syncing Windows and Mac.
rsync -z -r -v --delete --rsh="ssh -l xah" ~/web/ xah@169.254.125.147:~/web/
Note that -r is used instead of -a. The -r means recursive, all sub directories and files. Don't use -a because that will sync file owner, group, permissions, and others, but because Windows and unix have different permission systems and file systems, so -a is usually not what you want.
Here's a example of reverse direction.
rsync -z -a -v -t --rsh="ssh -l joe" joe@example.org:~/web/ ~/
Here's a example of syncing Windows and Mac.
rsync -z -r -v --delete --rsh="ssh -l xah" ~/web/ xah@169.254.125.147:~/web/
Note that -r is used instead of -a. The -r means recursive, all sub directories and files. Don't use -a because that will sync file owner, group, permissions, and others, but because Windows and unix have different permission systems and file systems, so -a is usually not what you want.
Here's a example of reverse direction.
rsync -z -a -v -t --rsh="ssh -l joe" joe@example.org:~/web/ ~/
copy files from one location to another, excluding certain files/folders:
rsync -av --progress sourcefolder /destinationfolder --exclude thefoldertoexclude --exclude anotherfoldertoexclude
rsync -av --progress sourcefolder /destinationfolder --exclude thefoldertoexclude --exclude anotherfoldertoexclude
Debian/Ubuntu:
#update system packages:sudo apt-get update
sudo apt-get upgrade
#alternative
sudo apt-get update && sudo apt-get upgrade -y #-y will provide the confirmation automatically
#search package name:
apt-cache search keyword
apt-get update
apt-get install
#uninstall packages
%sudo apt purge --auto-remove package0 package1 package2...
sleep:
delay in shell script%sleep 5s #delay 5 seconds, m: minute, h: hour, d: day.
ps:
%ps auxww #display in bsd formatThe aux options are as follows:
a = show processes for all users
u = display the process’s user/owner
x = also show processes not attached to a terminal
%ps -x #process owned by you
%timeout -s SIGKILL 10s command #force kill (SIGKILL) in 10 seconds, cannot be ignored by command
%timeout -k 10 5 command #send soft kill in 5s, if command not terminated, then force kill it 5s after that(10s=5+5).
%p4 diff2 -q //...@label_name_0 //...@label_name_1
ls -i
timeout:
%timeout 10s command #send soft kill (SIGTERM) in 10 seconds, this may be ignored by the command%timeout -s SIGKILL 10s command #force kill (SIGKILL) in 10 seconds, cannot be ignored by command
%timeout -k 10 5 command #send soft kill in 5s, if command not terminated, then force kill it 5s after that(10s=5+5).
Perforce:
#compare differences between two labels:%p4 diff2 -q //...@label_name_0 //...@label_name_1
ls:
#list inode of filels -i
git:
git clone https://github.com/github.com/libopencm3/libopencm3.git
git clone xxx new_dir_name
system task:
#show system info in ASCII format
screenfetch
#change password
sudo passwd root
sudo passwd account_name
#add a new user
sudo adduser user_name #ubuntu/debian
sudo useradd -m newuser #arch/manjaro
#add user to sudo group
sudo usermod -aG sudo username #debian/ubuntu
sudo usermod -aG wheel <username> #arch/manjaro
#test
su - username
#delete user
sudo deluser --remove-home newuser #debian/ubuntu
sudo userdel -r newuser #arch/manjaro
#shutdown system
%shutdown
#restart linux
%shutdown -r
#shutdown or restart immediately
%shutdown now
%shudown -r now
#scheduled shutdown
%shutdown 20 #shutdown in 20 mins
%shutdown -h 17:30 #shutdown at 17:30
%shutdown -r 17:30 #restart at 17:30
#cancel scheduled shutdown
%shutdown -c
#add shutdown wall message
%shutdown 'YOUR WALL MESSAGE'
Mount disk:
%lsblk #show the partition tables of all disks, note if there is partion on your disk, you need to mount the partition name instead of the disk name
%dmesg | tail #after connect the usb disk, run this command to find the name of the disk. normalled in /dev/sd*
%sudo mount /dev/sdb1 /mnt/pico
%umount device|directory. #safely unjoint device before you unplug it
List Devices:
%lspci #list pcie devices
#example to list macbook pcie devices
%lspci | grep -E 'Atheros|Broadcom'
%lsusb
Enable SSH remote connection:
%sudo apt install openssh-server
%sudo systemctl start ssh
%sudo systemctl enable ssh
%sudo systemctl status ssh #check current ssh status
Change default boot into Command line or GUI:
%systemctl get-default
%sudo systemctl set-default multi-user.target
%sudo systemctl reboot
#to switch back to gui, replace above command correspondingly
%sudo systemctl set-default graphical.target
Command history:
%cmd<Ctrl-r> #search revsersely through command history and auto complete
%<Esc> #put command on screen(<Enter> will execute that command
%<Ctrl-E> #similar to <Esc>
Command line settings:
#configure the looks of non gui mode command line:
sudo dpkg-reconfigure console-setup
#set time zone
timedatectl list-timezones
sudo timedatectl set-timezone "America/Los_Angeles"
prefix key Ctrl-b
#=========================================
#=============in terminal
#==========================================
%tmux ls # list all open tmux sessions
%tmux attach -t session-name #attach to a existing session
%tmux new-s session-name #create new session
%tmux rename-session -t session-old-name session-new-name
%tmux kill-session -t session-name
#==========================================
#=============inside tmux
#==========================================
#copy mode
%prefix [ #enter copy mode, where you can select and copy text in a pane
%prefix ] #paste the copied text to current pane
#sessions
prerfix s #list all session
prefix :kill-session #kill current session
prefix d #detach session
#windows
prefix w # list all windows
prefix window-number #switch to a selected window
prefix c #create a new window
prefix , #rename current window
prefix & #close current window
#panes
prefix z #toggle zoom the current pane to full screen
prefix Arrow-key #switch to pane
prefix x #close current pane
prefix % #create new vertical pane
prefix " #create new horizontal pane
Battery Status
%upower -e #same as —enumerate, enumerates object paths for devices
%upower -i device path #display information about the laptop battery (replace the path below with your battery's path
Thursday, April 4, 2019
Systemverilog Notes
- Systemverilog simulation steps
- asdfasd
- Gotcha: The Behavior of Foreach Loop Variables Depends on How the Array Dimensions Are Specified
- How is for-loop synthesizable in any HDL (Verilog)? How is it implemented in hardware?
- Solvnet Synopsys ETHERNET SVT UVM main page (also read the FAQ pdf, it's very detailed)
- Solvnet Synopsys Ethernet VIP Interface Reference
- Systemverilog process class: The process::self() function returns a handle to the current process, that is, a handle to the process making the call. SystemVerilog: Fine grain process control
- the repeat loop, expression is evaluated only once at the beginning, other loops, expression is re-evaluated in every iteration: loop evaluation, nandland for loop
- verilog generate: nandland generate example
- Virtual Class and upcasting
- data types:
- wire (a type of net):
- A net represent connections between hardware elements. Just as in real circuits, nets have values continuously driven on them by the outputs of devices that they are connected to.
- can only be driven with a continuous assignment statement
- a net is the only construct that resolves the effect of different states and strengths simultaneously driving the same signal.
- the behavior of a net is defined by a built-in resolution function using the values and strengths of all the drivers on a net. Every time there is a change on one of the drivers, the function is called to produce a resolved value. The function is create at elaboration (before simulation starts) and is based on the kind of net type, wand, wor, tril, etc.
- logic:
- can be driven by continuous assignments, gates, and modules, in addition to being a variables.
- can be used anywhere a net is used, except that a logic variable cannot be driven by multiple structural drivers (such as when you are modeling a bidirectional buss)
- continuous assignment, procedural assignment, and classes
- class based testbenches cannot have continuous assignments because classes are dynamically created objects and are not allowed to have structural constructs like continuous assignments.
- Although a class can read the resolved value of nets, it can only make procedural assignments to variables. Therefore, the testbench needs to create a variable that is continuously assigned to a wire (if you want to have multiple drives to that wire).
- procedural assignments to variables use the simple rule: last write wins. You are not allowed to make procedural assignemtns to nets because there is no way to represent how the value you assigning should be resolved with the other drivers.
- assign/deassign, force/release
- Another form of procedural continuous assignment is provided by the force and release procedural statements. These statements have a similar effect to the assign - deassign pair, but a force can be applied to nets as well as to variables.
- A force statement to a variable shall override a procedural assignment, continuous assignment or an assign procedural continuous assignment to the variable until a release procedural statement is executed on the variable.
- A force procedural statement on a net shall override all drivers of the net—gate outputs, module outputs, and continuous assignments—until a release procedural statement is executed on the net. When released, the net shall immediately be assigned the value determined by the drivers of the net.
- logic vs wire in an interface
- if your testbench drives an asynchronous signal in an interface with a procedural assignment, the signal must be a logic type. Signals in a clocking block are always synchronous and can be declared as logic or wire(?).
- wire can resolve multiple structural drivers, but logic cannot. choose depending on your user scenarios.
- procedures and procedural assignment
- initial_construct ::= initial statement_or_null
- always_construct ::= always_keyword statement
- always_keyword ::= always | always_comb | always_latch | always_ff
- final_construct ::= final function_statement
- function_declaration ::= function [ lifetime ] function_body_declaration
- task_declaration ::= task [ lifetime ] task_body_declaration
- In addition to these structured procedures, SystemVerilog contains other procedural contexts, such as coverage point expressions, assertion sequence match items, and action blocks.
- define and parameters for constant
- Assertions
- Modules and Hierarchy
- Bind
- Binding is like secretly instantiating a module/interface within another RTL file without disturbing the existing code. The binded module/interface is instantiated directly into the target module. How to bind inner signals from DUT?
- OOP
- singleton classes
- The singleton pattern is implemented by creating a class wit a method that creates a new instance of the class if one does not exist. If an instance already exists, it simply returns a handle to that object. To make sure that he object cannot be instantiated any other way, you must make the constructor protected. Don't make it local, because an extend class might need to access the constructor.
- Number
- Rules for expression types (from LRM). The following are the rules for determining the resulting type of an expression:
- — Expression type depends only on the operands. It does not depend on the left-hand side (if any).
- — Decimal numbers are signed.
- — Based numbers are unsigned, except where the s notation is used in the base specifier (as in 4'sd12 ).
- — Bit-select results are unsigned, regardless of the operands.
- — Part-select results are unsigned, regardless of the operands even if the part-select specifies the entire vector.
- logic [15:0] a;
- logic signed [7:0] b;
- initial
- a = b[7:0]; // b[7:0] is unsigned and therefore zero-extended
- — Concatenate results are unsigned, regardless of the operands.
- — Comparison and reduction operator results are unsigned, regardless of the operands.
- — Reals converted to integers by type coercion are signed
- — The sign and size of any self-determined operand are determined by the operand itself and independent of the remainder of the expression.
- — For non-self-determined operands, the following rules apply:
- — If any operand is real, the result is real.
- — If any operand is unsigned, the result is unsigned, regardless of the operator.
- — If all operands are signed, the result will be signed, regardless of operator, except when specified otherwise.
Saturday, March 23, 2019
MacOS use notes
files system:
- type absolute path: Command + Shift + g while in any Finder window or select "Go to Folder…"
- files search in spotlight to exclude a certain folder: 1) Launch System Preferences from the Apple menu and choose the “Spotlight” preference panel, 2) Click on the “Privacy” tab, 3) Drag & drop folders or drives to exclude from the Spotlight index, or click the “+” plus icon in the corner to manually select hard drives or directories
screeshot:
- Shift-Command (⌘)-5 on your keyboard to see all the controls you need to capture still images and record video of your screen.
terminal:
- open files from terminal: open -a TextEdit filename should do the trick. The -a flag specifies any application you want, so it's applicable to any number of situations, including ones where TextEdit isn't the default editor.
macbook pro battery drain fast during sleep:
- pmset for macos power management controls
- Excessive battery drain while sleeping after 10.13.4 update
- is your Mac waking on its own, draining battery and then just plain powering down?
Friday, March 1, 2019
Systemverilog defines for use in variable names
How do form Variable names by using defines in system verilog:
https://stackoverflow.com/questions/20759707/how-do-form-variable-names-by-using-defines-in-system-verilog
https://verificationacademy.com/forums/systemverilog/define-macros-usage
https://stackoverflow.com/questions/15373113/how-to-create-a-string-from-a-pre-processor-macro
Below is from LRM:
The `define macro text can also include `" , `\`" , and ``.
An `" overrides the usual lexical meaning of " and indicates that the expansion shall include the quotation mark, substitution of actual arguments, and expansions of embedded macros. This allows string literals to be constructed from macro arguments.
A mixture of `" and " is allowed in the macro text, however the use of " always starts a string literal and
must have a terminating " . Any characters embedded inside this string literal, including `" , become part of the string in the replaced macro text. Thus, if " is followed by `" , the " starts a string literal whose last character is ` and is terminated by the " of `" .
The `define macro text can also include `" , `\`" , and ``.
An `" overrides the usual lexical meaning of " and indicates that the expansion shall include the quotation mark, substitution of actual arguments, and expansions of embedded macros. This allows string literals to be constructed from macro arguments.
A mixture of `" and " is allowed in the macro text, however the use of " always starts a string literal and
must have a terminating " . Any characters embedded inside this string literal, including `" , become part of the string in the replaced macro text. Thus, if " is followed by `" , the " starts a string literal whose last character is ` and is terminated by the " of `" .
A `\`" indicates that the expansion should include the escape sequence \" . For example:
`define msg(x,y) `"x: `\`"y`\`"`"
An example of using this `msg macro is:
$display(`msg(left side,right side));
The preceding example expands to:
$display("left side: \"right side\"");
A `` delimits lexical tokens without introducing white space, allowing identifiers to be constructed from arguments. For example:
`define append(f) f``_master
An example of using this `append macro is:
`append(clock)
This example expands to:
clock_master
The `include directive can be followed by a macro, instead of a string literal:
`define home(filename) `"/home/mydir/filename`"
`include `home(myfile)
i paraphrase from the above link, and pay attention to the so called token identifier in systemverilog:
Quote:
So this means if i just use ``I , the expansion of macro `abc(1,a) would be :
assign abc[1] == R.duI_clk_x . Since its not defined as a separate token ??
Yes, that would be the result.
Quote:
Both R and I are arguments to the macro so why you say that no ``R`` is needed where as ``I`` is needed. Is it because the left hand side has no dependency on R or is it because R is not breaking the lexical variable ?
Correct again. What you call a lexical variable is what the compiler calls a token identifier. The compiler grabs text in chunks called tokens, before it knows what the identifier is (variable, typedef, module name). An identifier starts with a letter, followed by any number of alpha-numeric characters, as well as _(underscore). Any other character ends the token.
Quote:
So here ``I`` is not used, why ?
Only [I] is needed because I is surrounded by characters that are not part of token identifiers.
I think the issue comes when the macros are used with generate loop.
The complete code is :
`define WB_DUT_U_ASSIGN(phy_i,idx)\
assign b[phy_i] = `DUT_PATH.Ilane``idx``.a;\
genvar wb
generate
for(wb=0;wb<8;wb++) begin:wb_a
`WB_DUT_U_ASSIGN(wb,wb)
end
endgenerate
Macros are preprocessor directives. There are expanded before parsing any Verilog/SystemVerilog syntax.
In reply to kvssrohit: As I said before, macros get expanded as text for any generate processing. `dev_(i) gets expanded as top.i.XXX
The only way to achieve what you want withing SystemVerilog is to restructure your instance names into an array and access them with proper indexing. top[i].
Otherwise there are other macro processing tools that you can use to generate the identifier names you are looking for. But that becomes quite a maintenance headache.
genvar i;
for (i=0; i<=31; i=i+1) begin: gen_force
initial
force top[i].zzz = 1'b1;
end
I don't think you will be able to do mix compiler time defines with run-time variables. There is no space/tab to distinguish between 2 lexical tokens(VAR ,str_var). When you put space the expression will become illegal.
You can use parameterized macro but you cannot use a variable while calling it.
Saturday, January 5, 2019
Learning Python
0. Set up python env
install homebrew on macosinstall python3 with homebrew: brew install python3
install python modules with pip3, pip3 is included in python3: pip3 install requests
0.1 Trick Nice for testing out python scripts in command lind
python << EOFimport sys
print(sys.version)
EOF
input([prompt]) #evaluates to a string equal to the user's input text. if prompt is not empty, it will print prmpt w/o newline
str(), int(), float()
print() print an empty line
print([object [, object]* [, sep=' '] [, end='\n'] [, file=sys.stdout] [, flush=Falsue])
** #(exponent)
// #(integraer division/floored quotient, towards negative infinity)
Strings
'Alice' + 'Bob' #concatenations, 'AliceBob'
'Alice' * 3 #string replication, 'AliceAliceAlice'
Command line arguments:
https://www.tutorialspoint.com/python/python_command_line_arguments.htm
sys.args
getopt
boolean: True/False, and, or, not
after any math and comparison operators evaluate, Python evaluates the not operators first, then the and operators, and then the or operators.
Loops:
if/elif/else
if a<8:
a = a*2
elif a<10:
a = a*8
else:
a = a-1
general tenary form: value_true if <test> else value_false
print('home') if is_home else print('not home')
while
break
continue
for i in range()
range(start, stop, step)
Ending a program early with sys.exit()
the colon and the indentation design hisotry:
http://python-history.blogspot.com/2011/07/karin-dewar-indentation-and-colon.html
suite
#order counts. Just as non-default arguments have to precede default arguments, so *args must come before **kwargs.
#positional arguments, keywoard(named) arguments
#Python args and kwargs: Demystified
return
None #absence of a vaule, only value of the NoneType data type
*args #varying number of a tuple of positional arguments
1. Basics
Math operators:** #(exponent)
// #(integraer division/floored quotient, towards negative infinity)
Strings
'Alice' + 'Bob' #concatenations, 'AliceBob'
'Alice' * 3 #string replication, 'AliceAliceAlice'
Command line arguments:
https://www.tutorialspoint.com/python/python_command_line_arguments.htm
sys.args
getopt
2. Flow Control
comparison: ==, !=, <, >, <=, >=boolean: True/False, and, or, not
after any math and comparison operators evaluate, Python evaluates the not operators first, then the and operators, and then the or operators.
Loops:
if/elif/else
if a<8:
a = a*2
elif a<10:
a = a*8
else:
a = a-1
general tenary form: value_true if <test> else value_false
print('home') if is_home else print('not home')
while
break
continue
for i in range()
range(start, stop, step)
Ending a program early with sys.exit()
the colon and the indentation design hisotry:
http://python-history.blogspot.com/2011/07/karin-dewar-indentation-and-colon.html
3. Functions
def name([arg,... arg=value,... *arg, **kwarg]):suite
#order counts. Just as non-default arguments have to precede default arguments, so *args must come before **kwargs.
#positional arguments, keywoard(named) arguments
#Python args and kwargs: Demystified
return
None #absence of a vaule, only value of the NoneType data type
*args #varying number of a tuple of positional arguments
**kwargs #similar to *args, but the iterables are a dictionary of keyword arguments.
keyword arguments: #often used for optional parameters
print('Hello', 'cats', 'dogs', sep=',' end='')
Exception handling:
def spam(divideBy):
try:
return 42 / divideBy
except ZeroDivisionError:
print('Error: Invalid argument.')
#Unpacking With the Asterisk Operators: * & **
print('Hello', 'cats', 'dogs', sep=',' end='')
Exception handling:
def spam(divideBy):
try:
return 42 / divideBy
except ZeroDivisionError:
print('Error: Invalid argument.')
#Unpacking With the Asterisk Operators: * & **
# extract_list_body.py
my_list = [1, 2, 3, 4, 5, 6]
a, *b, c = my_list
# merging_lists.py
# merging_lists.py
my_first_list = [1, 2, 3]
my_second_list = [4, 5, 6]
my_merged_list = [*my_first_list, *my_second_list]
# merging_dicts.py
# merging_dicts.py
my_first_dict = {"A": 1, "B": 2}
my_second_dict = {"C": 3, "D": 4}
my_merged_dict = {**my_first_dict, **my_second_dict}
# string_to_list.py
# string_to_list.py
a = [*"RealPython"]
Local Scope: variables assigned in a called function are said to exist in that function's local scope
Global Scope: variables assigned outside all functions are said to exist in the global scope
Python scoping rules:
Local variables cannot be used in the global scope
local scopes cannot use variables in other local scopes
global vairables can be read from a local scope
local and global variables with the same name
global statement to declare a variables as global in a function
how to tell whether a variable is in local scope or global scope:
if a variable is being used in global scope, then it is always a global variable.
if there is a global statement for that variable in a function, it is a global variable.
otherwise, if the variable is used in an assignment statement in the function, it is a local variable.
But if the variable is not used in an assignment statement, it is a global variable
in a function, a variable will either always be global or always be local.
nonlocal statement for nested functions to access local variables of its enclosing function
There is only one global scope, and it is created when your program begins
a local scope is created whenever a function is called.
for-loop scoping issue:
the for-loop makes assignments to the variables in the target list. [...] Names in the target list are not deleted when the loops finished, but if the sequence is empty, they will not have been assigned to at all by the loop.
https://eli.thegreenplace.net/2015/the-scope-of-index-variables-in-pythons-for-loops/
https://stackoverflow.com/questions/4198906/python-list-comprehension-rebind-names-even-after-scope-of-comprehension-is-thi
tuple ('a', 'b', 'c')
slices:
0-based indexing, http://python-history.blogspot.com/2013/10/why-python-uses-0-based-indexing.html
4. Scoping
Python does not have block scoping. Python does not have nested lexical scopes below the level of a function, unlike some other languages (C and its progeny, for example).Local Scope: variables assigned in a called function are said to exist in that function's local scope
Global Scope: variables assigned outside all functions are said to exist in the global scope
Python scoping rules:
Local variables cannot be used in the global scope
local scopes cannot use variables in other local scopes
global vairables can be read from a local scope
local and global variables with the same name
global statement to declare a variables as global in a function
how to tell whether a variable is in local scope or global scope:
if a variable is being used in global scope, then it is always a global variable.
if there is a global statement for that variable in a function, it is a global variable.
otherwise, if the variable is used in an assignment statement in the function, it is a local variable.
But if the variable is not used in an assignment statement, it is a global variable
in a function, a variable will either always be global or always be local.
nonlocal statement for nested functions to access local variables of its enclosing function
There is only one global scope, and it is created when your program begins
a local scope is created whenever a function is called.
for-loop scoping issue:
the for-loop makes assignments to the variables in the target list. [...] Names in the target list are not deleted when the loops finished, but if the sequence is empty, they will not have been assigned to at all by the loop.
https://eli.thegreenplace.net/2015/the-scope-of-index-variables-in-pythons-for-loops/
https://stackoverflow.com/questions/4198906/python-list-comprehension-rebind-names-even-after-scope-of-comprehension-is-thi
5. Lists, tuples, mutable and immutable data type, passing references
lists ['a', 'b', 'c'], []tuple ('a', 'b', 'c')
slices:
0-based indexing, http://python-history.blogspot.com/2013/10/why-python-uses-0-based-indexing.html
Half-open intervals: https://www.cs.utexas.edu/~EWD/transcriptions/EWD08xx/EWD831.html
negative indexs (-1 the last index, -2 second-to-last index)
spam[:2], spam[1:], spam[-3], spam[:]
get a list's length with len()
list concatenation and replication:
[1, 2, 3] + ['a', 'b', 'c'] #[1, 2, 3, 'a', 'b', 'c']
['a', 'b', 'c'] * 2 #['a', 'b', 'c', 'a', 'b', 'c']
del statement to delete values at an index in a list:
del spam[2]
for-loop with list:
for i in [1, 3, 4, 5]
for i in range(len(spma))
in and not in operator:
'howdy' in ['hello', howdy', 'hans']
if name not in spam
multiple assignment trick:
size, color, disposition = spam #spam is a list of 3 elemnts
list methods,
#l is a list name below
l.index(value) #find the first appearance
l.append(value), l.insert(index, value),
l.remove(value) #remove the first appearance
l.sort(key=str.lower, reverse=True/False) #default in ASCII order, for alphabetical order, need to treat all in lowercase, reverse default True.
l.count(X) #return the number of occurences of X in the list l
l.clear() #renive akk items from list l
Python uses references whenever variables must store values of mutable data types, such as lists or dictionaries. For values of immutable data types such as strings, integers, or tuples, Python variables will store the value itself.
del dict[key]
color in somedict #short hand for check if key exists in dict
get(key, fallback value)
setdefault(KEY, default value)
pretty printing: pprint.pprint(), pprint.pformat()
negative indexs (-1 the last index, -2 second-to-last index)
spam[:2], spam[1:], spam[-3], spam[:]
get a list's length with len()
list concatenation and replication:
[1, 2, 3] + ['a', 'b', 'c'] #[1, 2, 3, 'a', 'b', 'c']
['a', 'b', 'c'] * 2 #['a', 'b', 'c', 'a', 'b', 'c']
del statement to delete values at an index in a list:
del spam[2]
for-loop with list:
for i in [1, 3, 4, 5]
for i in range(len(spma))
in and not in operator:
'howdy' in ['hello', howdy', 'hans']
if name not in spam
multiple assignment trick:
size, color, disposition = spam #spam is a list of 3 elemnts
list methods,
#l is a list name below
l.index(value) #find the first appearance
l.append(value), l.insert(index, value),
l.remove(value) #remove the first appearance
l.sort(key=str.lower, reverse=True/False) #default in ASCII order, for alphabetical order, need to treat all in lowercase, reverse default True.
l.count(X) #return the number of occurences of X in the list l
l.clear() #renive akk items from list l
Python uses references whenever variables must store values of mutable data types, such as lists or dictionaries. For values of immutable data types such as strings, integers, or tuples, Python variables will store the value itself.
6. dictionary {'a':4, 'b':4, 'c':5}
keys(), values(), items() #return not true list, list likedel dict[key]
color in somedict #short hand for check if key exists in dict
get(key, fallback value)
setdefault(KEY, default value)
pretty printing: pprint.pprint(), pprint.pformat()
dict = {}
dict['a'] = ...
Unlike sequences, which are indexed by a range of numbers, dictionaries are indexed by keys, which can be any immutable type; strings and numbers can always be keys. Tuples can be used as keys if they contain only strings, numbers, or tuples; if a tuple contains any mutable object either directly or indirectly, it cannot be used as a key. You can’t use lists as keys, since lists can be modified in place using index assignments, slice assignments, or methods like append() and extend().
raw strings:
r'that is carol\s cat' #all escape characters are ignored, backslashes and the first character after it is included.
Concatenate strings:
a) "string0" "string1" "string2" #this form may span multiple lines if parenthesized
b) "string0" "string1" + "string2"
string formatting: '{0}, {1}, {2:.2f}'.format(42, 'spam', 1/3.0)
string formatting since python3.6 (string interpolation syntax): f'{self.id} ({self.title})'
multiple line strings with tripple quotes: """
multiline comments: '''
indexing and slicing strings, same as lists
upper(), lower(), isupper(), islower() #do not change string, but return a new string
isX(), isalpha(), isalnum(), isdecimal(), isspace(), istitgle()
startswith() and endswith()
join(), split(sep=None, Maxsplit=-1):
https://note.nkmk.me/en/python-split-rsplit-splitlines-re/
', '.join(['cats', 'rats', 'bats'])
[MyABCnameABCisABCSimon'.split('ABC')#resulting list does not include 'ABC'
#the argument is omitted, it will be separated by whitespace. Whitespace include spaces, newlines \n and tabs \t, and consecutive whitespace are processed together.
strip([chars]), rstrip(), lstrip() #remove whitespaces
#The chars argument is a string specifying the set of characters to be removed. If omitted or None, the chars argument defaults to removing whitespace. The chars argument is not a prefix or suffix; rather, all combinations of its values are stripped
#'www.example.com'.strip('cmowz.') evaluates to 'example'
#non-empty strings evaluate to True
pattern = r'lsakdfjldfj'
mo = re.search(pattern, 'text to search')
mo.group(), mo.group(0) #return entire matched text
mo.group(1),
mo.groups() #return a tuple of all the group matches
| #matching multiple groups, e.g. r'Bat(man|mobile|copter|bat)'
? #optional matching, matching 0 or 1 of the group preceding ?
. #match 1 of any character, except for newline(unless pass re.DOTALL options)
* #match 0 or more with *
+ #match 1 or more with +
{3} #match specific repetitions of the group preciding {}
{3,5} #macth 3, 4, or 5 repetitions
{,5}
{3,}
{3,5}? or *? or +? #non-greedy matching
^ #match start of line
$ $match end of line
.* #match everything greedy way
[aeiouAEIOU] # character class
[^aeiouAEIOU] #negative character class, will match anything not in the character class
re.findall(pattern, text):
#if there are groups in the regular expression, then findall() will return a list of tuples. each tuple represents a found match, and it's items are the matched strings for each group in the regex.
pattern = r'(\d\d\d)-(\d\d\d)-(\d\d\d\d)'
re.findall(pattern, 'Cell: 415-555-9999 Work: 212-555-000')
results is [('415', '555', '9999'), ('212', '555', '0000')]
Substituting strings with sub():
pattern = r'Agent (\w)\w*'
re.sub(pattern, r'\1****', 'Agent Alice told Agent Carol that Agent Eve was a double agent')
#above returns 'A**** told C**** that E**** was a double agent'
ignore whitespace and comments inside regex string:
regex = re.compile(r'''(
(\d{3}) #alsdkfj
(\s+) #laksdjf
)''', re.VERBOSE)
re.search(r'lskdj', string, re.IGNORECAE | re.DOTALL | re.VERBOSE)
re.split(pattern, string [, maxsplit=0]) #more powerful than str.split
#re.split('\d+', s_nums)
#re.split('[-+#]', s_marks)
#re.split('XXX|YYY|ZZZ', s_strs)
os.path.join('user', 'bin', 'spam')
os.getcwd()
os.chdir()
absolute path vs relative path
. and ..
os.makedirs() #will create any necessary folders in order to ensure that the ful path exists
os.path.abspath(path)
os.path.isabs(path)
os.path.relpath(path, [start])
os.path.dirname(path)
os.path.basename(path):
/usr/bin/python3 #dirname: /usr/bin/ basename: python3
os.path.split() #return a tuple with two strings, (dirname, basename)
os.path.sep #system folder separator
os.path.getsize(path) #size in bytes
os.listdir(path) #list of filename strings for each file in the path argument
os.path.exists(path)
os.path.isfile(path)
os.path.isdir(path)
File reading and writing:
open(path, [c(reate)/r(read)/w(rite)/a(ppend)]/wb(write binary)]) #return a File object
File.read() #entire contents of a file as a string value
File.readlines() #list of string values from the file, one string for each line of text
File.write()
File.close()
Two methods to explicitly close files after use:
1) try/finally
myfile = open(r'some_file_path', 'w')
try:
...use myfile...
finally:
myfile.close()
2) with statement
with open(r'some_file_path', 'w') as a, open(r'some_file_path', 'w') as b:
...proces a (auto-closed on suite exit)...
Shelve module #store any type of data with string keys, dictionary like
import shelve
shelfFile = shelve.open('mydata')
cats = ['Zophie', 'Pooka', 'Simon']
shelfFile['cats'] = cats
shelfFile.close()
import zipfile
zf = zipfile.ZipFile('zip_file_name')
zf.namelist()
zf.read('file_name') #return single file content in bytes datatype
zinfo = zf.getinfo('file_name')
zinfo.file_size
zinfo.compress_size
zinfo.comment #return bytes datatype
extract files
Extracting from ZIP files:
zf = zipfile.ZipFile('zip_file_name')
zf.extractall([destination_dir_path]) #extract all files in the zip file to current or destination dir
zf.extract('single_file_name', 'destination_dir_path') #extract a single file from zip file
Creating and adding to ZIP files:
newzip = zipfile.ZipFile('new.zip', 'w(rite)/a(ppend)') #write mode erase all existing content, append mode will add file to zip
newzip.write('file_to_add_to_zip', compress_type=zipfile.ZIP_DEFLATED)
newzip.close()
Bytes type to string
b'xxx'.decode() #python 3 default using utf-8 encoding
b'xxx'.decode(encoding='utf-8') #specify the encoding to use
String decode:
'xxxx'.decode('bz2') #treat strings as bz2 compressed file content and decompress it
Linux file command to identify:
file.write('xxx', 'w')
file f #identify file type and it's related program to open
csvreader = csv.reader(file_object, delimiter='\t')
csvwriter = csv.writer(file_object, delimiter='\t')
#For large CSV files, you’ll want to use the reader object in a for loop. This avoids loading the entire file into memory at once.
for line in csvreader:
csvwriter.writerow(line)
csvreader = csv.DictReader(file_object, fieldnames=None, restkey=None, restval=None, dialect='excel', *args, **kwds)
#Create an object that operates like a regular reader but maps the information in each row to a dict whose keys are given by the optional fieldnames parameter. If fieldnames is omitted, the values in the first row of file f will be used as the fieldnames.
#All other optional or keyword arguments are passed to the underlying
fieldnames = ['first name', 'last name']
csvwriter = csv.DictWriter(file_object, field_names=fieldnames, delimiter='\t')
csvwriter.writeheader()
for line in csvreader:
del line['email']
csvwriter.writerow(line)
video tutorials: Python SQLite Tutorial: Complete Overview - Creating a Database, Table, and Running Queries
#two ways to commit, or rollback if exception happens
#a: explicit writing try statement
try:
codd_id = create_customer(con, 'Edgar', 'Codd')
codd_order = create_order(con, codd_id, '1969-01-12')
codd_li = create_lineitem(con, codd_order, 4, 1, 16.99)
# commit the statements
con.commit()
except:
# rollback all database actions since last commit
con.rollback()
raise RuntimeError("Uh oh, an error occurred ...")
#b: using with statement and context manager
with conn:
conn.execute(xxxx)
#automatically commit if no exception, otherwise will rollback
To create element or subelement:
import xml.etree.ElementTree as ET
# build a tree structure
root = ET.Element("html")
head = ET.SubElement(root, "head")
title = ET.SubElement(head, "title")
title.text = "Page Title"
body = ET.SubElement(root, "body")
body.set("bgcolor", "#ffffff")
body.text = "Hello, World!"
# wrap it in an ElementTree instance, and save as XML
tree = ET.ElementTree(root)
tree.write("page.xhtml")
When creating a new element, you can pass in element attributes using keyword arguments. The previous example is better written as:
elem = Element("tag", first="1", second="2")
Atrribute:
The Element type provides shortcuts for attrib.get, attrib.keys, and attrib.items. There’s also a set method, to set the value of an element attribute:
from elementtree.ElementTree import Element
elem = Element("tag", first="1", second="2")
# print 'first' attribute
print elem.attrib.get("first")
# same, using shortcut
print elem.get("first")
# print list of keys (using shortcuts)
print elem.keys()
print elem.items()
# the 'third' attribute doesn't exist
print elem.get("third")
print elem.get("third", "default")
# add the attribute and try again
elem.set("third", "3")
print elem.get("third", "default")
Search for subelement:
Read and Write XML files:
The Element type can be used to represent XML files in memory. The ElementTree wrapper class is used to read and write XML files.
To load an XML file into an Element structure, use the parse function:
tree = parse(filename)
elem = tree.getroot()
You can also pass in a file handle (or any object with a read method):
file = open(filename, "r")
tree = parse(file)
elem = tree.getroot()
The parse method returns an ElementTree object. To get the topmost element object, use the getroot method.
In recent versions of the ElementTree module, you can also use the file keyword argument to create a tree, and fill it with contents from a file in one operation:
tree = ElementTree(file=filename)
elem = tree.getroot()
To save an element tree back to disk, use the write method on the ElementTree class. Like the parse function, it takes either a filename or a file object (or any object with a write method):
tree.write(outfile)
If you want to write an Element object hierarchy to disk, wrap it in an ElementTree instance:
from elementtree.ElementTree import Element, SubElement, ElementTree
html = Element("html")
body = SubElement(html, "body")
ElementTree(html).write(outfile)
Note that the standard element writer creates a compact output. There is no built-in support for pretty printing or user-defined namespace prefixes in the current version, so the output may not always be suitable for human consumption (to the extent XML is suitable for human consumption, that is).
#read the python doc to understand the following parameters!
write(file, encoding="us-ascii", xml_declaration=None, default_namespace=None, method="xml", *, short_empty_elements=True)
One way to produce nicer output is to add whitespace to the tree before saving it; see the indent function on the Element Library Functions page for an example.
To convert between XML and strings, you can use the XML, fromstring, and tostring helpers:
from elementtree.ElementTree import XML, fromstring, tostring
elem = XML(text)
elem = fromstring(text) # same as XML(text)
text = tostring(elem)
When in doubt, print it out (print(ET.tostring(root, encoding='utf8').decode('utf8'))) - use this helpful print statement to view the entire XML document at once. It helps to check when editing, adding, or removing from an XML.
class and id Selectors:
In the CSS, a class selector is a name preceded by a full stop (“.”) and an ID selector is a name preceded by a hash character (“#”).
The difference between an ID and a class is that an ID can be used to identify one element, whereas a class can be used to identify more than one.
with expression [as variable]
[, expression [as variable]]*:
suite
The with statement wraps a nested block of code in a context manager, which can run block entry actions, and ensure that block exit actions are run whether exceptions are raised or not. with can be alternative to try/finally for exit actions, but only for objects having context managers.
expression is assumed to return an object that supports the context management protocol. This object may also return a value that will be assigned to the name variable if the optional as clause is present. Classes may define custom context managers, and some built-in types such as files and threads provide context managers with exit actions that close files, release thread locks, etc.:
list comprehensions
Unlike sequences, which are indexed by a range of numbers, dictionaries are indexed by keys, which can be any immutable type; strings and numbers can always be keys. Tuples can be used as keys if they contain only strings, numbers, or tuples; if a tuple contains any mutable object either directly or indirectly, it cannot be used as a key. You can’t use lists as keys, since lists can be modified in place using index assignments, slice assignments, or methods like append() and extend().
7. Strings
Escape character: \n #commonly referred to as a singular escape characterraw strings:
r'that is carol\s cat' #all escape characters are ignored, backslashes and the first character after it is included.
Concatenate strings:
a) "string0" "string1" "string2" #this form may span multiple lines if parenthesized
b) "string0" "string1" + "string2"
string formatting: '{0}, {1}, {2:.2f}'.format(42, 'spam', 1/3.0)
string formatting since python3.6 (string interpolation syntax): f'{self.id} ({self.title})'
multiple line strings with tripple quotes: """
multiline comments: '''
indexing and slicing strings, same as lists
upper(), lower(), isupper(), islower() #do not change string, but return a new string
isX(), isalpha(), isalnum(), isdecimal(), isspace(), istitgle()
startswith() and endswith()
join(), split(sep=None, Maxsplit=-1):
https://note.nkmk.me/en/python-split-rsplit-splitlines-re/
', '.join(['cats', 'rats', 'bats'])
[MyABCnameABCisABCSimon'.split('ABC')#resulting list does not include 'ABC'
#the argument is omitted, it will be separated by whitespace. Whitespace include spaces, newlines \n and tabs \t, and consecutive whitespace are processed together.
strip([chars]), rstrip(), lstrip() #remove whitespaces
#The chars argument is a string specifying the set of characters to be removed. If omitted or None, the chars argument defaults to removing whitespace. The chars argument is not a prefix or suffix; rather, all combinations of its values are stripped
#'www.example.com'.strip('cmowz.') evaluates to 'example'
#non-empty strings evaluate to True
8. Regular expression
What is the difference between re.search and re.match?pattern = r'lsakdfjldfj'
mo = re.search(pattern, 'text to search')
mo.group(), mo.group(0) #return entire matched text
mo.group(1),
mo.groups() #return a tuple of all the group matches
| #matching multiple groups, e.g. r'Bat(man|mobile|copter|bat)'
? #optional matching, matching 0 or 1 of the group preceding ?
. #match 1 of any character, except for newline(unless pass re.DOTALL options)
* #match 0 or more with *
+ #match 1 or more with +
{3} #match specific repetitions of the group preciding {}
{3,5} #macth 3, 4, or 5 repetitions
{,5}
{3,}
{3,5}? or *? or +? #non-greedy matching
^ #match start of line
$ $match end of line
.* #match everything greedy way
[aeiouAEIOU] # character class
[^aeiouAEIOU] #negative character class, will match anything not in the character class
re.findall(pattern, text):
#if there are groups in the regular expression, then findall() will return a list of tuples. each tuple represents a found match, and it's items are the matched strings for each group in the regex.
pattern = r'(\d\d\d)-(\d\d\d)-(\d\d\d\d)'
re.findall(pattern, 'Cell: 415-555-9999 Work: 212-555-000')
results is [('415', '555', '9999'), ('212', '555', '0000')]
Substituting strings with sub():
pattern = r'Agent (\w)\w*'
re.sub(pattern, r'\1****', 'Agent Alice told Agent Carol that Agent Eve was a double agent')
#above returns 'A**** told C**** that E**** was a double agent'
ignore whitespace and comments inside regex string:
regex = re.compile(r'''(
(\d{3}) #alsdkfj
(\s+) #laksdjf
)''', re.VERBOSE)
re.search(r'lskdj', string, re.IGNORECAE | re.DOTALL | re.VERBOSE)
re.split(pattern, string [, maxsplit=0]) #more powerful than str.split
#re.split('\d+', s_nums)
#re.split('[-+#]', s_marks)
#re.split('XXX|YYY|ZZZ', s_strs)
9. Reading and writing files
system folder structures:os.path.join('user', 'bin', 'spam')
os.getcwd()
os.chdir()
absolute path vs relative path
. and ..
os.makedirs() #will create any necessary folders in order to ensure that the ful path exists
os.path.abspath(path)
os.path.isabs(path)
os.path.relpath(path, [start])
os.path.dirname(path)
os.path.basename(path):
/usr/bin/python3 #dirname: /usr/bin/ basename: python3
os.path.split() #return a tuple with two strings, (dirname, basename)
os.path.sep #system folder separator
os.path.getsize(path) #size in bytes
os.listdir(path) #list of filename strings for each file in the path argument
os.path.exists(path)
os.path.isfile(path)
os.path.isdir(path)
File reading and writing:
open(path, [c(reate)/r(read)/w(rite)/a(ppend)]/wb(write binary)]) #return a File object
File.read() #entire contents of a file as a string value
File.readlines() #list of string values from the file, one string for each line of text
File.write()
File.close()
Two methods to explicitly close files after use:
1) try/finally
myfile = open(r'some_file_path', 'w')
try:
...use myfile...
finally:
myfile.close()
2) with statement
with open(r'some_file_path', 'w') as a, open(r'some_file_path', 'w') as b:
...proces a (auto-closed on suite exit)...
Shelve module #store any type of data with string keys, dictionary like
import shelve
shelfFile = shelve.open('mydata')
cats = ['Zophie', 'Pooka', 'Simon']
shelfFile['cats'] = cats
shelfFile.close()
10. Organizing files
Zip files:import zipfile
zf = zipfile.ZipFile('zip_file_name')
zf.namelist()
zf.read('file_name') #return single file content in bytes datatype
zinfo = zf.getinfo('file_name')
zinfo.file_size
zinfo.compress_size
zinfo.comment #return bytes datatype
extract files
Extracting from ZIP files:
zf = zipfile.ZipFile('zip_file_name')
zf.extractall([destination_dir_path]) #extract all files in the zip file to current or destination dir
zf.extract('single_file_name', 'destination_dir_path') #extract a single file from zip file
Creating and adding to ZIP files:
newzip = zipfile.ZipFile('new.zip', 'w(rite)/a(ppend)') #write mode erase all existing content, append mode will add file to zip
newzip.write('file_to_add_to_zip', compress_type=zipfile.ZIP_DEFLATED)
newzip.close()
Bytes type to string
b'xxx'.decode() #python 3 default using utf-8 encoding
b'xxx'.decode(encoding='utf-8') #specify the encoding to use
String decode:
'xxxx'.decode('bz2') #treat strings as bz2 compressed file content and decompress it
Linux file command to identify:
file.write('xxx', 'w')
file f #identify file type and it's related program to open
11. CSV Files
import csvcsvreader = csv.reader(file_object, delimiter='\t')
csvwriter = csv.writer(file_object, delimiter='\t')
#For large CSV files, you’ll want to use the reader object in a for loop. This avoids loading the entire file into memory at once.
for line in csvreader:
csvwriter.writerow(line)
csvreader = csv.DictReader(file_object, fieldnames=None, restkey=None, restval=None, dialect='excel', *args, **kwds)
#Create an object that operates like a regular reader but maps the information in each row to a dict whose keys are given by the optional fieldnames parameter. If fieldnames is omitted, the values in the first row of file f will be used as the fieldnames.
#All other optional or keyword arguments are passed to the underlying
reader instance. this means all reader/writer arguments are accepted. same goes for DictWriterfieldnames = ['first name', 'last name']
csvwriter = csv.DictWriter(file_object, field_names=fieldnames, delimiter='\t')
csvwriter.writeheader()
for line in csvreader:
del line['email']
csvwriter.writerow(line)
12. SQLITE database
tutorials: A great tutorial (comprehensive), A SQLite Tutorial with Pythonvideo tutorials: Python SQLite Tutorial: Complete Overview - Creating a Database, Table, and Running Queries
import sqlite3
conn = sqlite3.connect('/dir_path/xxx.db') #db in files
conn = sqlite3.connect(':memory:') #every time run script, the db start from fresh in memory
cur = conn.cursor()
cur.execute("""CREATE table employees(
first TEXT,
last TEXT,
pay INTEGER
)""")
#two ways with placeholders for parameterized queries
cur.execute("INSERT INTO employees VALUES (?, ?, ?)", ("John", "Doe", 80000))
cur.execute("INSERT INTO employees VALUES (:first, :last, :pay)", {first:"John", last:"Doe", pay:80000})
cur.execute("SELECT * FROM employees WHERE last=?", ("Doe", ))
cur.execute("SELECT * FROM employees WHERE last=:last", {last:"Doe"})
"Parameterized queries are an important feature of essentially all database interfaces to modern high level programming languages such as the sqlite3 module in Python. This type of query serves to improve the efficiency of queries that are repeated several times. Perhaps more important, they also sanitize inputs that take the place of the ? placeholders which are passed in during the call to the execute method of the cursor object to prevent nefarious inputs leading to SQL injection.
I feel compelled to give one additional piece of advice as a student of software craftsmanship. When you find yourself doing multiple database manipulations (INSERTs in this case) in order to accomplish what is actually one cumulative task (ie, creating an order) it is best to wrap the subtasks (creating customer, order, then line items) into a single database transaction so you can either commit on success or rollback if an error occurs along the way."
conn = sqlite3.connect('/dir_path/xxx.db') #db in files
conn = sqlite3.connect(':memory:') #every time run script, the db start from fresh in memory
cur = conn.cursor()
cur.execute("""CREATE table employees(
first TEXT,
last TEXT,
pay INTEGER
)""")
#two ways with placeholders for parameterized queries
cur.execute("INSERT INTO employees VALUES (?, ?, ?)", ("John", "Doe", 80000))
cur.execute("INSERT INTO employees VALUES (:first, :last, :pay)", {first:"John", last:"Doe", pay:80000})
cur.execute("SELECT * FROM employees WHERE last=?", ("Doe", ))
cur.execute("SELECT * FROM employees WHERE last=:last", {last:"Doe"})
"Parameterized queries are an important feature of essentially all database interfaces to modern high level programming languages such as the sqlite3 module in Python. This type of query serves to improve the efficiency of queries that are repeated several times. Perhaps more important, they also sanitize inputs that take the place of the ? placeholders which are passed in during the call to the execute method of the cursor object to prevent nefarious inputs leading to SQL injection.
I feel compelled to give one additional piece of advice as a student of software craftsmanship. When you find yourself doing multiple database manipulations (INSERTs in this case) in order to accomplish what is actually one cumulative task (ie, creating an order) it is best to wrap the subtasks (creating customer, order, then line items) into a single database transaction so you can either commit on success or rollback if an error occurs along the way."
#two ways to commit, or rollback if exception happens
#a: explicit writing try statement
try:
codd_id = create_customer(con, 'Edgar', 'Codd')
codd_order = create_order(con, codd_id, '1969-01-12')
codd_li = create_lineitem(con, codd_order, 4, 1, 16.99)
# commit the statements
con.commit()
except:
# rollback all database actions since last commit
con.rollback()
raise RuntimeError("Uh oh, an error occurred ...")
with conn:
conn.execute(xxxx)
#automatically commit if no exception, otherwise will rollback
12. XML with xml.etree.ElementTree
Elements and Element Trees
Python XML with ElementTree: Beginner's Guide
What characters do I need to escape in XML documents?: follow Welbog's and kjhughes's answers
Python XML with ElementTree: Beginner's Guide
What characters do I need to escape in XML documents?: follow Welbog's and kjhughes's answers
XML is an inherently hierarchical data format, and the most natural way to represent it is with a tree. ET has two objects for this purpose – ElementTree represents the whole XML document as a tree, and Element represents a single node in this tree. Interactions with the whole document (reading, writing, finding interesting elements) are usually done on the ElementTree level. Interactions with a single XML element and its sub-elements is done on the Element level.
The Element type is a flexible container object, designed to store hierarchical data structures in memory. The type can be described as a cross between a list and a dictionary.
The Element type is a flexible container object, designed to store hierarchical data structures in memory. The type can be described as a cross between a list and a dictionary.
- Tag It is a string representing the type of data being stored
- Attributes Consists of a number of attributes stored as dictionaries
- Text String A text string having information that needs to be displayed
- Tail String Can also have tail strings if necessary
- Child Elements Consists of a number of child elements stored as sequences
ElementTree is a class that wraps the element structure and allows conversion to and from XML.
To create element or subelement:
import xml.etree.ElementTree as ET
# build a tree structure
root = ET.Element("html")
head = ET.SubElement(root, "head")
title = ET.SubElement(head, "title")
title.text = "Page Title"
body = ET.SubElement(root, "body")
body.set("bgcolor", "#ffffff")
body.text = "Hello, World!"
# wrap it in an ElementTree instance, and save as XML
tree = ET.ElementTree(root)
tree.write("page.xhtml")
When creating a new element, you can pass in element attributes using keyword arguments. The previous example is better written as:
elem = Element("tag", first="1", second="2")
Atrribute:
The Element type provides shortcuts for attrib.get, attrib.keys, and attrib.items. There’s also a set method, to set the value of an element attribute:
from elementtree.ElementTree import Element
elem = Element("tag", first="1", second="2")
# print 'first' attribute
print elem.attrib.get("first")
# same, using shortcut
print elem.get("first")
# print list of keys (using shortcuts)
print elem.keys()
print elem.items()
# the 'third' attribute doesn't exist
print elem.get("third")
print elem.get("third", "default")
# add the attribute and try again
elem.set("third", "3")
print elem.get("third", "default")
Search for subelement:
- find(pattern) returns the first subelement that matches the given pattern, or None if there is no matching element.
- findtext(pattern) returns the value of the text attribute for the first subelement that matches the given pattern. If there is no matching element, this method returns None.
- findall(pattern) returns a list (or another iterable object) of all subelements that match the given pattern and are direct children of the current element. powerful is that this can take XPath expressions. e.g. root.findall("./genre/decade/movie/[year='1992']") will find the movie with attribute of year='1992'. python doc: supported XPath synctax
Read and Write XML files:
The Element type can be used to represent XML files in memory. The ElementTree wrapper class is used to read and write XML files.
To load an XML file into an Element structure, use the parse function:
tree = parse(filename)
elem = tree.getroot()
You can also pass in a file handle (or any object with a read method):
file = open(filename, "r")
tree = parse(file)
elem = tree.getroot()
The parse method returns an ElementTree object. To get the topmost element object, use the getroot method.
In recent versions of the ElementTree module, you can also use the file keyword argument to create a tree, and fill it with contents from a file in one operation:
tree = ElementTree(file=filename)
elem = tree.getroot()
To save an element tree back to disk, use the write method on the ElementTree class. Like the parse function, it takes either a filename or a file object (or any object with a write method):
tree.write(outfile)
If you want to write an Element object hierarchy to disk, wrap it in an ElementTree instance:
from elementtree.ElementTree import Element, SubElement, ElementTree
html = Element("html")
body = SubElement(html, "body")
ElementTree(html).write(outfile)
Note that the standard element writer creates a compact output. There is no built-in support for pretty printing or user-defined namespace prefixes in the current version, so the output may not always be suitable for human consumption (to the extent XML is suitable for human consumption, that is).
#read the python doc to understand the following parameters!
write(file, encoding="us-ascii", xml_declaration=None, default_namespace=None, method="xml", *, short_empty_elements=True)
One way to produce nicer output is to add whitespace to the tree before saving it; see the indent function on the Element Library Functions page for an example.
To convert between XML and strings, you can use the XML, fromstring, and tostring helpers:
from elementtree.ElementTree import XML, fromstring, tostring
elem = XML(text)
elem = fromstring(text) # same as XML(text)
text = tostring(elem)
When in doubt, print it out (print(ET.tostring(root, encoding='utf8').decode('utf8'))) - use this helpful print statement to view the entire XML document at once. It helps to check when editing, adding, or removing from an XML.
Appendix I Book References
References: online resources from the book: https://nostarch.com/automatestuffresourcesAppendix II HTML Tags and CSS Selectors
A good reference for HTM/CSS: https://www.htmldog.com/guides/css/intermediate/classid/class and id Selectors:
In the CSS, a class selector is a name preceded by a full stop (“.”) and an ID selector is a name preceded by a hash character (“#”).
The difference between an ID and a class is that an ID can be used to identify one element, whereas a class can be used to identify more than one.
Appendix III Python Concepts
with statements:with expression [as variable]
[, expression [as variable]]*:
suite
The with statement wraps a nested block of code in a context manager, which can run block entry actions, and ensure that block exit actions are run whether exceptions are raised or not. with can be alternative to try/finally for exit actions, but only for objects having context managers.
expression is assumed to return an object that supports the context management protocol. This object may also return a value that will be assigned to the name variable if the optional as clause is present. Classes may define custom context managers, and some built-in types such as files and threads provide context managers with exit actions that close files, release thread locks, etc.:
list comprehensions
Appendix III Bitwise Operation
Python save number in Two's complement with unlimited precision.
bitwise operators:
&, |, ^, ~,<<
>>
#right shift is arithmetic shift instead of logical shift. so the
#leftmost bit is filled with original value. this will make difference
#when dealing with negative numbers.
Appendix IV Type Conversion
Number to Strings:
hex(X), oct(X), bin(X), str(X)
chr(I) #integer to character
String to Number:
int(S [, base]), float(S)
ord(C) #character to Unicode value (including ASCII)
Subscribe to:
Comments (Atom)